演示视频
点击下列链接直接观看
截图演示
由于精力有限,我只录制了中文的演示视频。 然后下面的截图呢,就只有英文文字标注了。大家有各种问题交流,除了在Github,还可以加入咱们的QQ群: 560675626 (为避免无关人员骚扰,加群申请填写暗号 大胖哥是个好人 来通过验证)。
打开和导入数据文件
投图计算之前,必然要先打开文件导入数据,操作如截图所示。
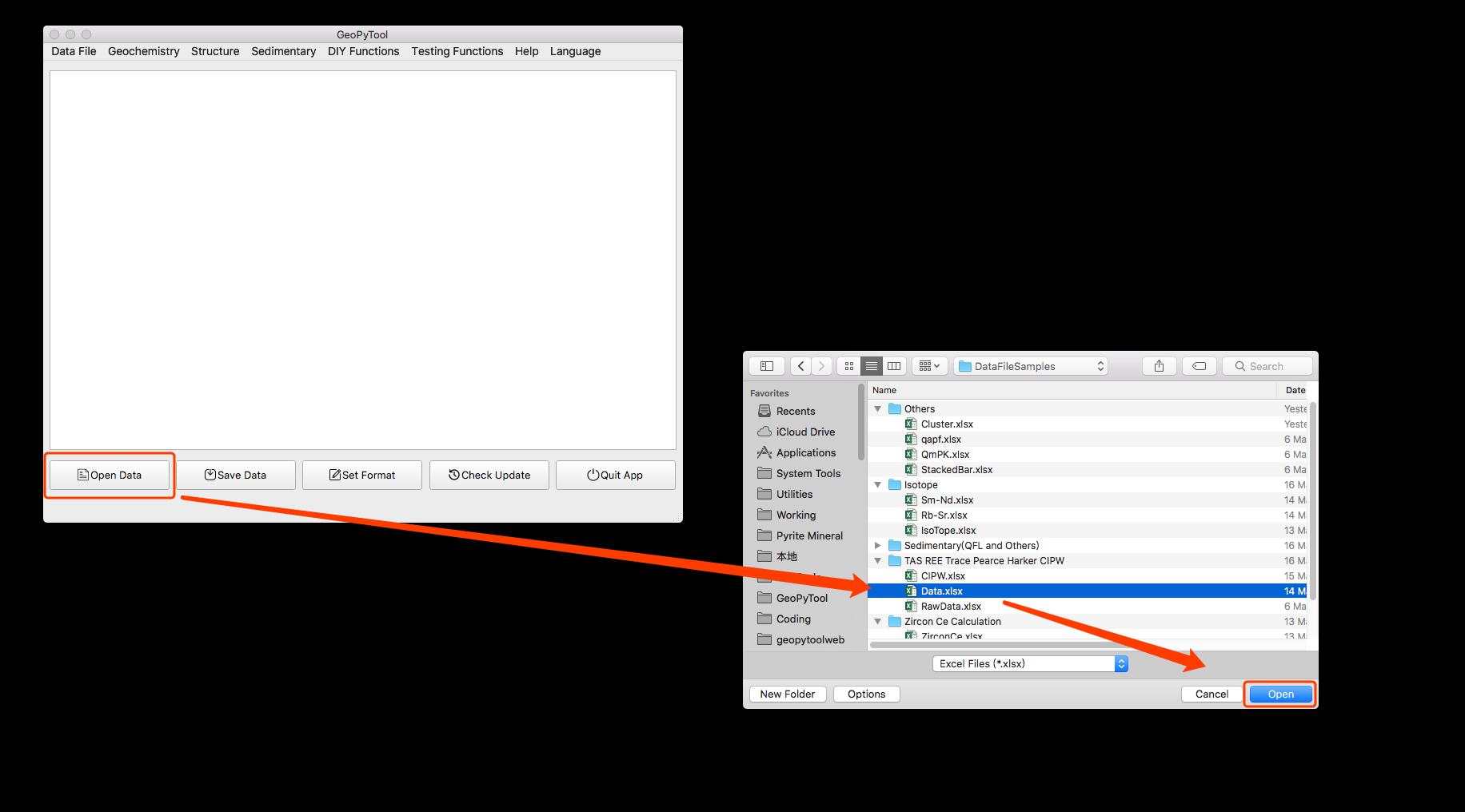
数据格式可以使 Xlsx/Xls 或者 CSV,但如果你用的是Windows 系统,最好用 CSV 格式, UTF-8 编码,无BOM,否则可能出现表格中大量 NAN 的问题,这或许是由于 pandas 在 Windows 上对数据表格的解析方式和 Linux 以及 macOS 上不一样导致的。
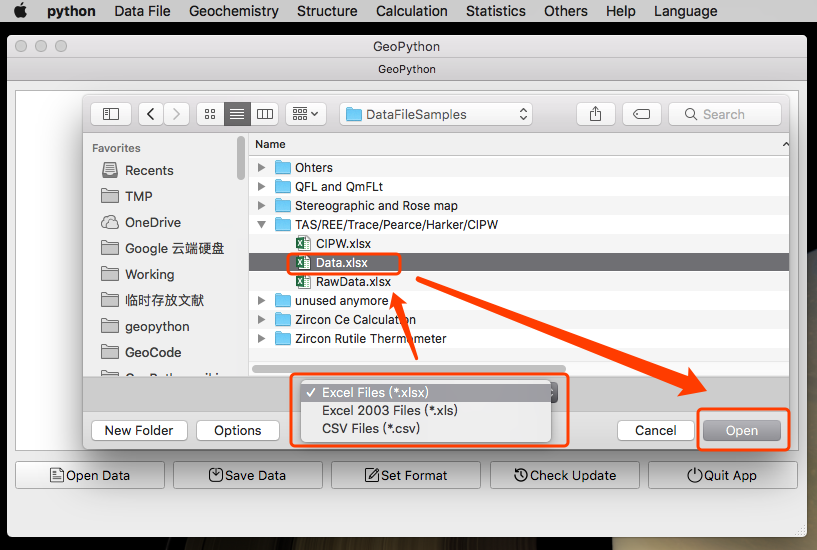
数据单位
氧化物之类的项目(例如 SiO2, TiO2, Al2O3, Fe2O3, FeO, MnO, MgO, CaO Na2O, K2O, P2O5, LOI, Total 等等)数据单位是重量百分比(wt%)。
但千万要遵循数据模板的格式!
一定不要在使用的数据中包含% 之类乱七八糟的符号!
其他元素的单位 (比如 Li, Be, Sc, V, Cr, Co, Ni, Cu, Zn, Ga, Rb, Sr, Y, Zr, Nb, Cs, Ba, La, Ce, Pr, Nd, Sm, Eu, Gd, Tb, Dy, Ho, Er, Tm, Yb, Lu, Hf, Ta, Tl, Pb, Th, U) 都是 ppm。
设置数据添加分组颜色等信息
如果原始数据没有添加这些分类信息,程序自然不知道该怎么分。所以你需要自己添加 Label/Color/Marker/Style/Alapha/Width等项目。好在这些只需要点击一下 设置数据(英文版为 Set Fromat ) 按钮,就可以添加好这些项目了,然后你还需要根据自己的样品情况自己去分组。可别来问该怎么分组,你自己的样品自己做主!
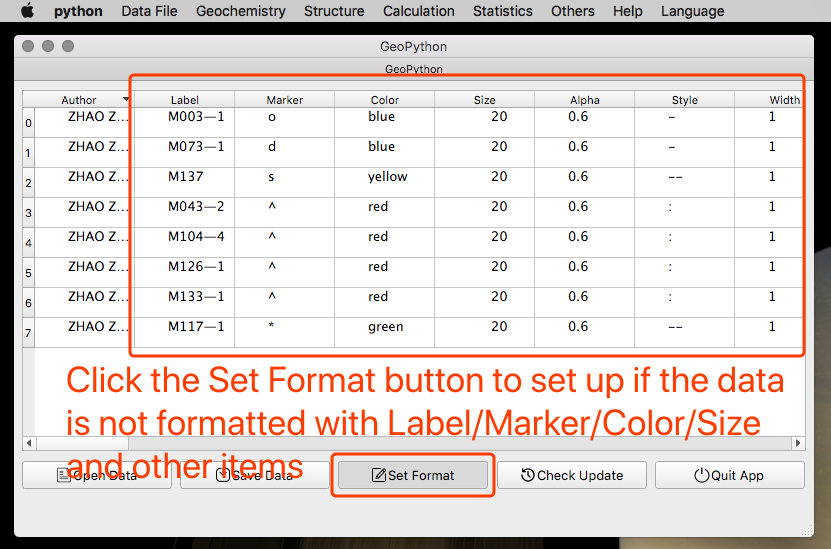
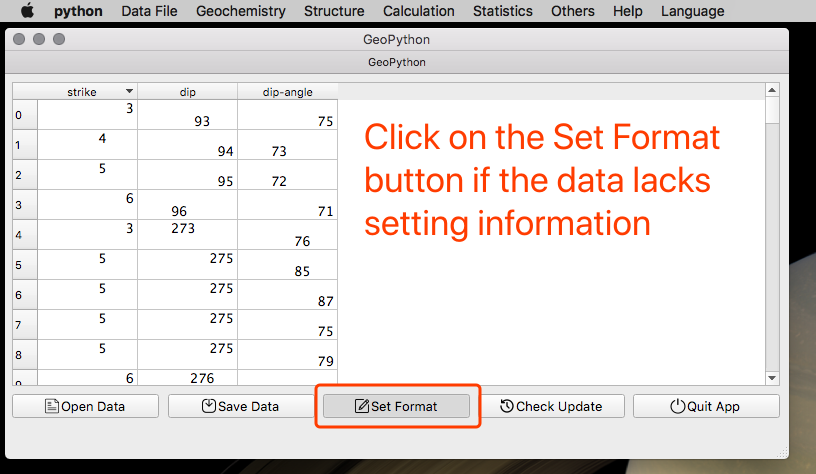
数据设置详解
在模板 Data File Samples当中,所有的文件都包含有下面的内容:
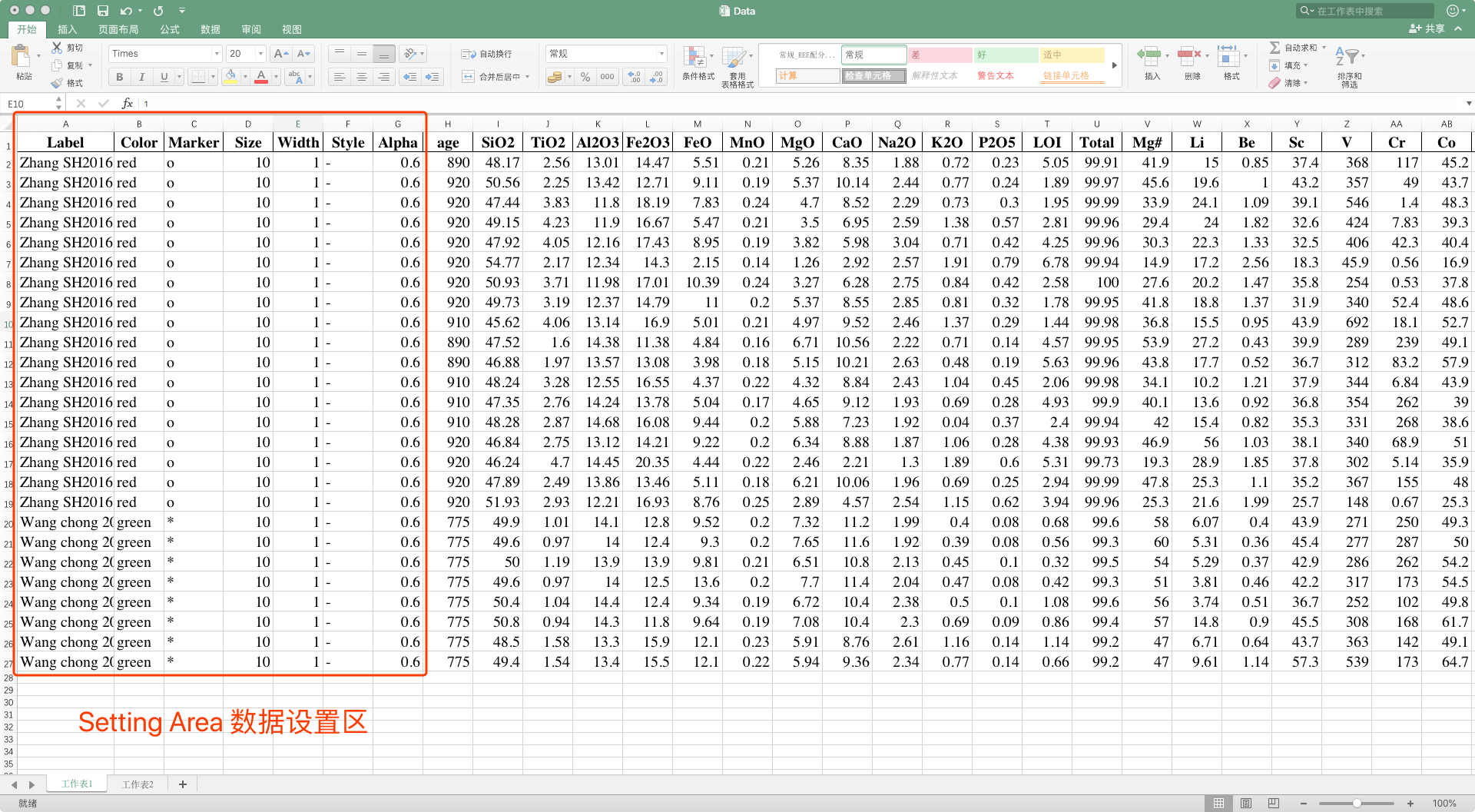
Label: 控制分组信息,会显示在图例上Color: 点和线的颜色Marker: 点的形状Size: 点的大小Width: 线的粗细Style: 线的形状Alpha: 点和线的透明度
除了上面这七个设置列之外,其他列的数据都必须是数值的!!!
Label
可以设置成任何文本
Color
只能从下面列表中选择 'blue','green','red','cyan','magenta','yellow','black','white'.
效果如下图所示:
Color:

Size, Width, 和 Alpha
都必须是数值。其中用于 Size 和 Width 的单位是 pt.
Size 一般至少设置为 '10', Width 可以设为 '1'.
Alpha 要设置在 '0' 到 '1'直接,例如,如果设置 Alpha 为 '0.4' 就意味着透明度为 40%.
Marker 和 Style
这两个有点复杂,可以设置为下面表格中的内容。
Marker :

Style:

上述各项的设置效果如下图所示:
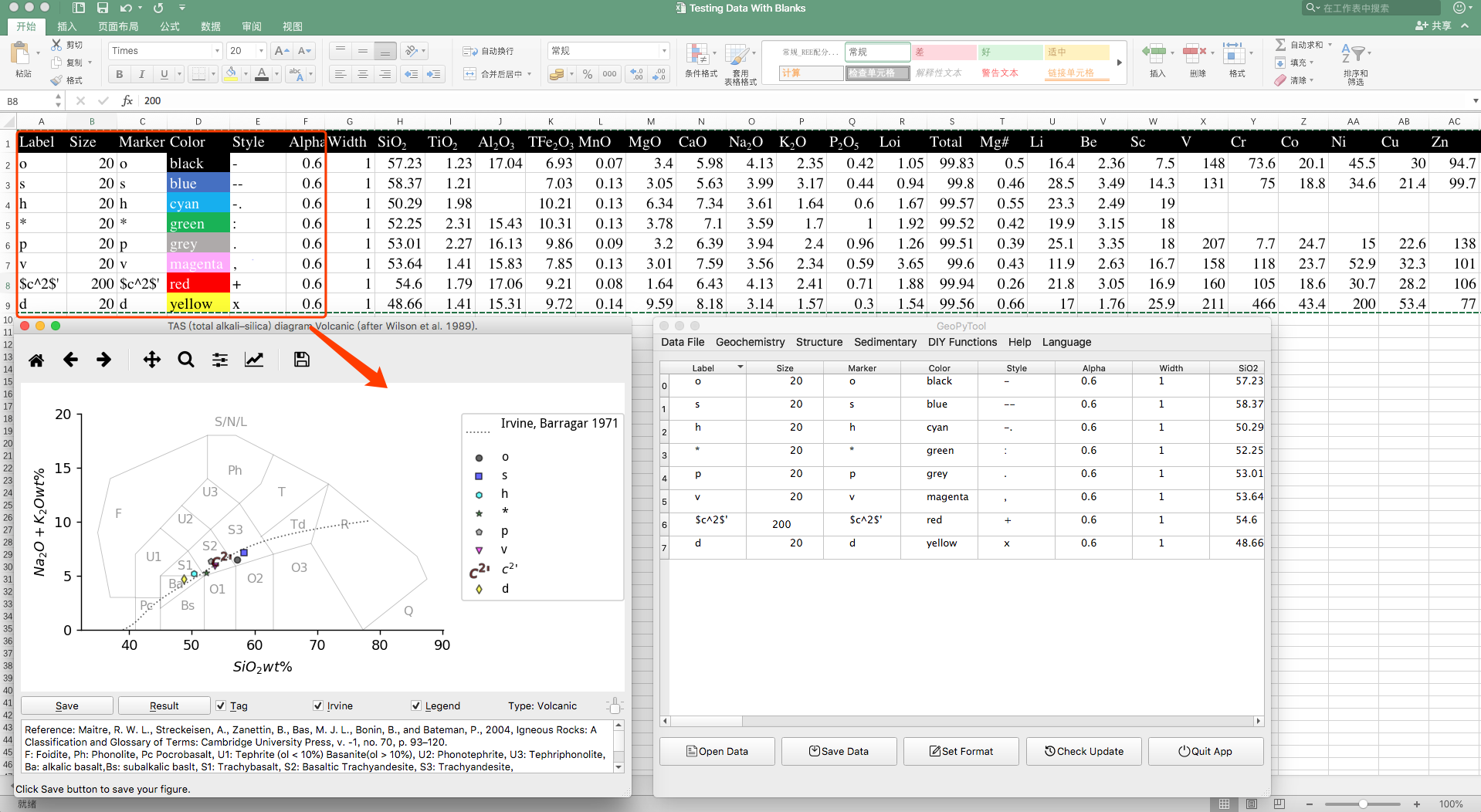
图片坐标轴调整
每个生成的图的顶部都有一个菜单栏,可以利用上面的按钮来调整坐标轴位置和图幅标题等等,如下图所示:
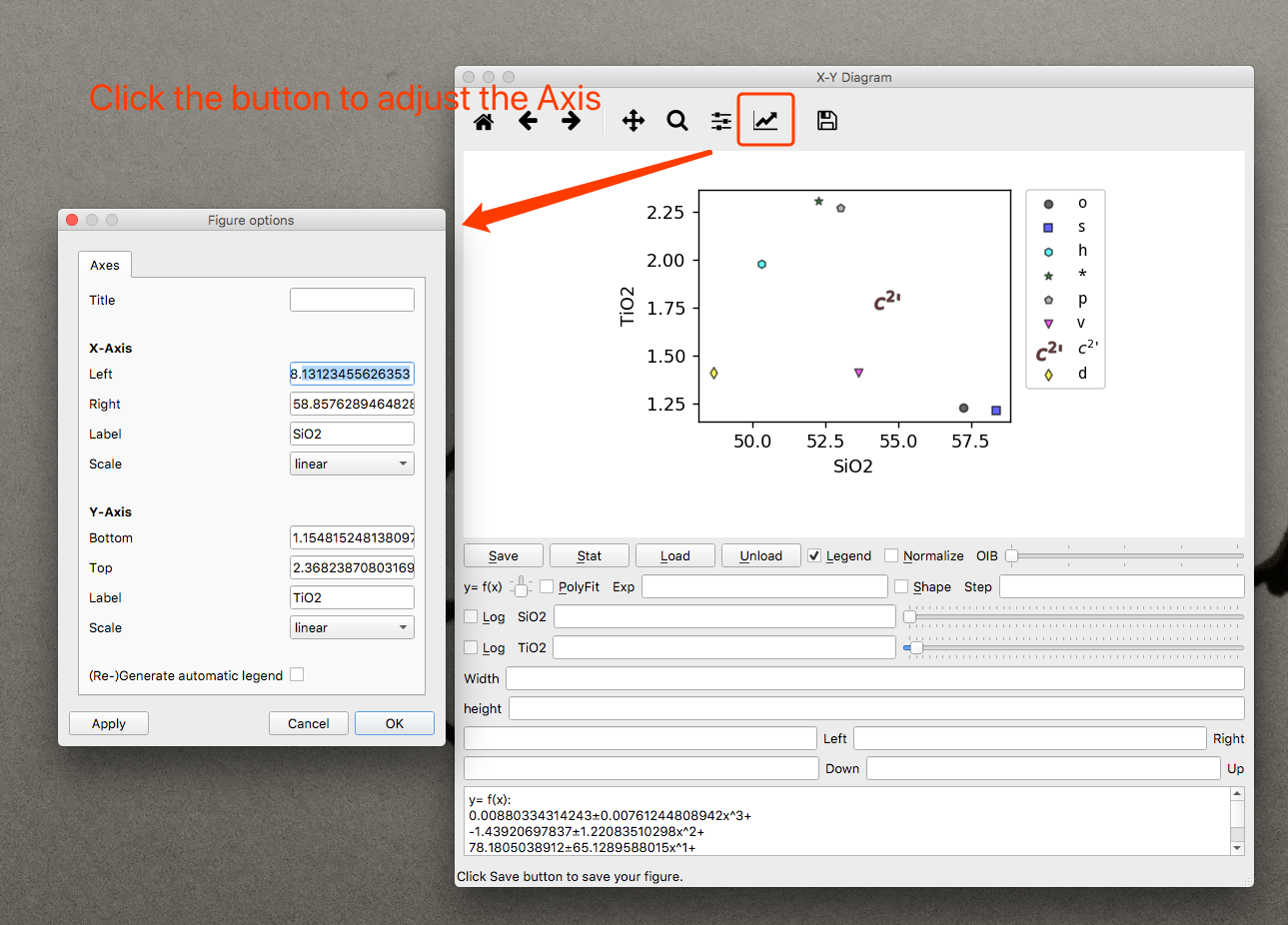
点击要用的功能来运行
设置完了格式之后,就可以点击你要用的功能来运行了。
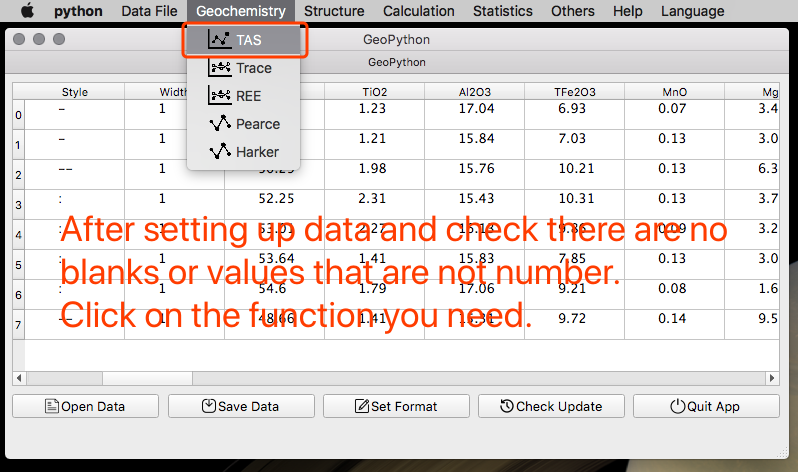
TAS硅碱图解/REE稀土模式图/微量元素蛛网图
These functions are quite commonly used and the details are shown as the picture below.
这些功能都很简单,没啥可说的,如下图所示。另外微量元素有两种排列方式,一种是 Cs-Lu,另外一个是 Rb-Lu,反正有个选框,可以用来切换,自己找找吧,就在 Reset 那个按钮旁边哈。
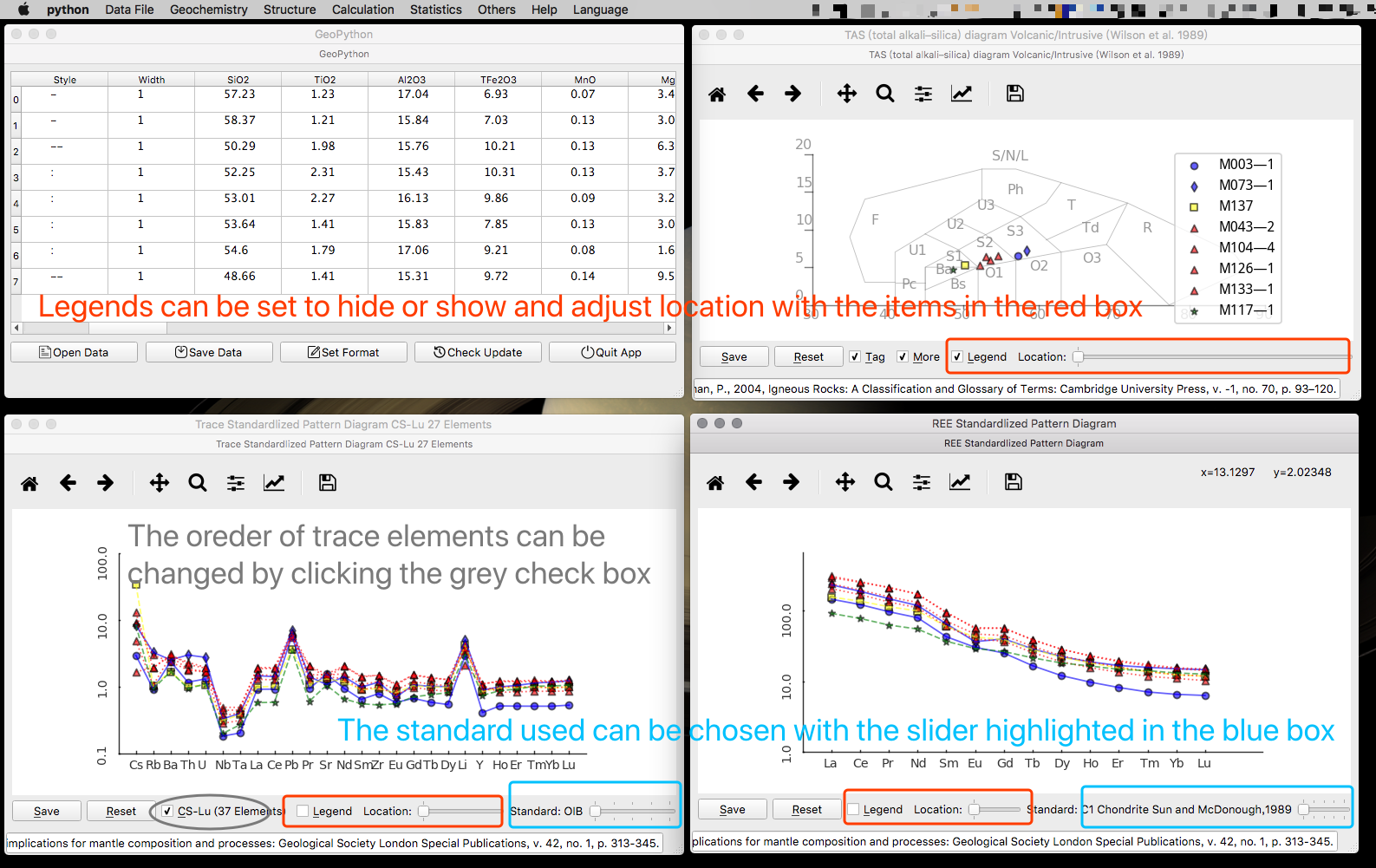
点击下图所示按钮查看分类判别结果, 在弹出的表格中点击 Pie 按钮可以查看结果的比例饼图.
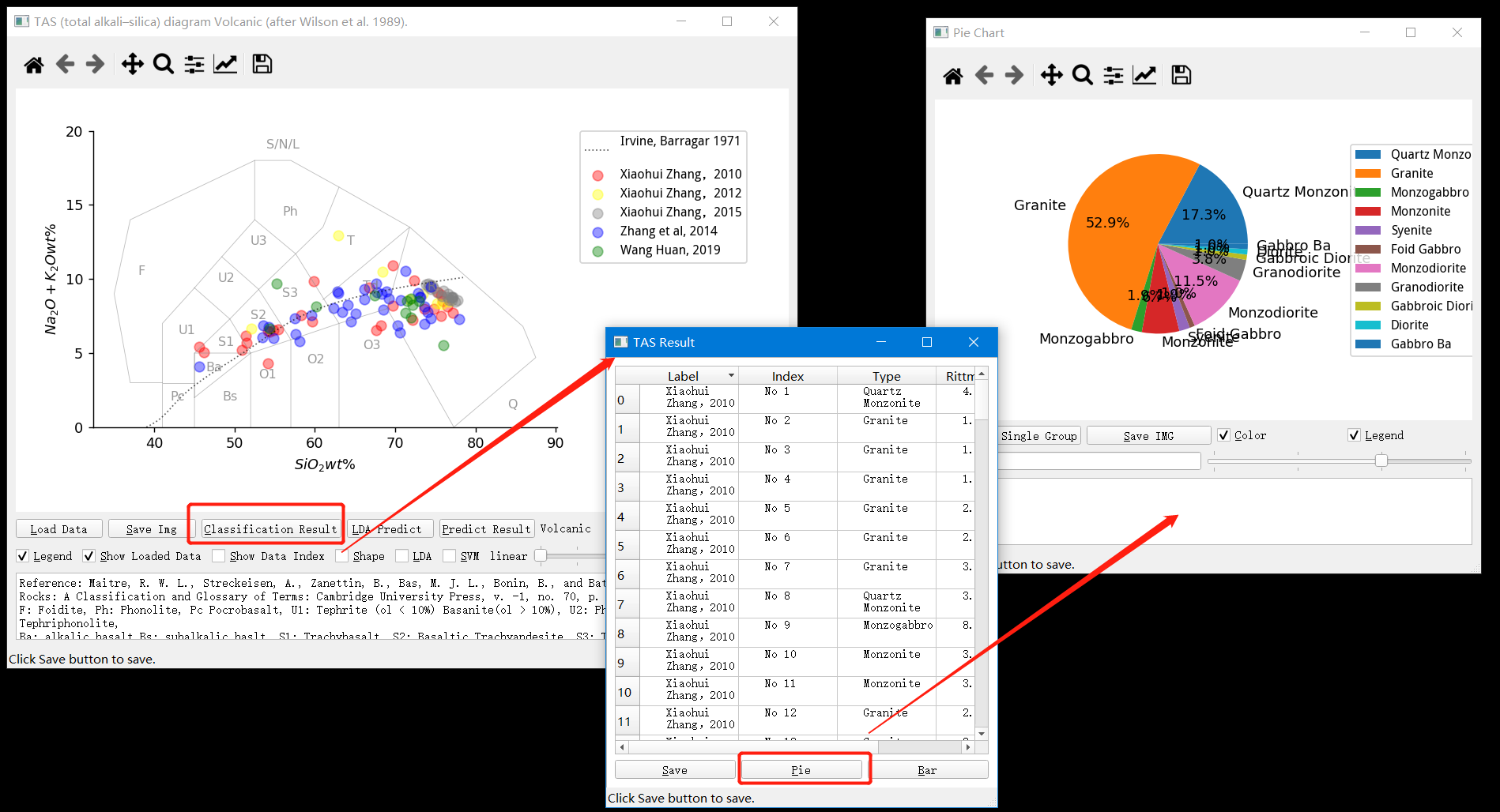
Pearce 图解
无非是用了几种不同元素组合而已。右下角的滑块通过滑动可以获得这几种不同组合,当然都是点击 save 来存储生成的图像了。太简单了,没啥可说的。
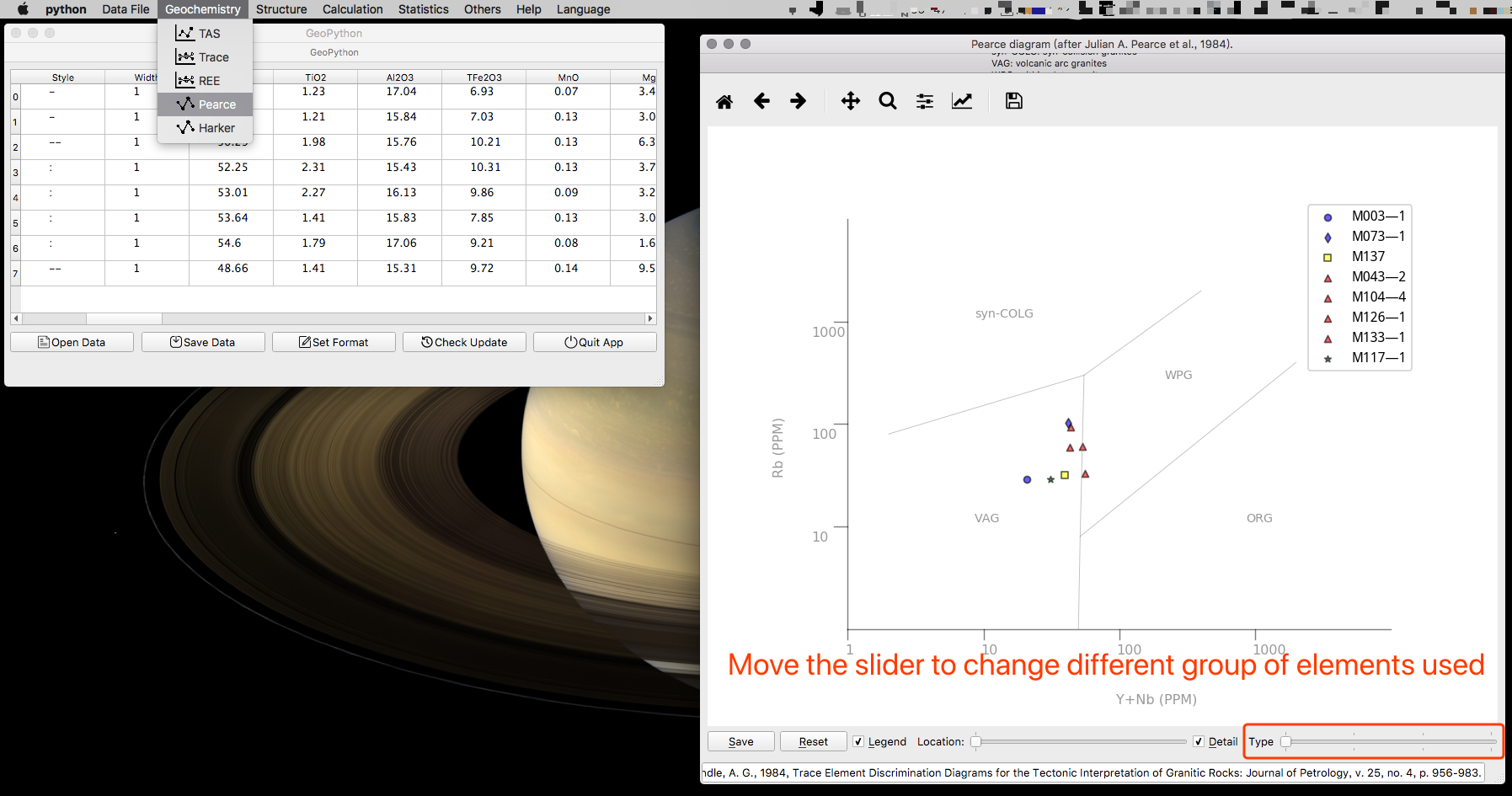
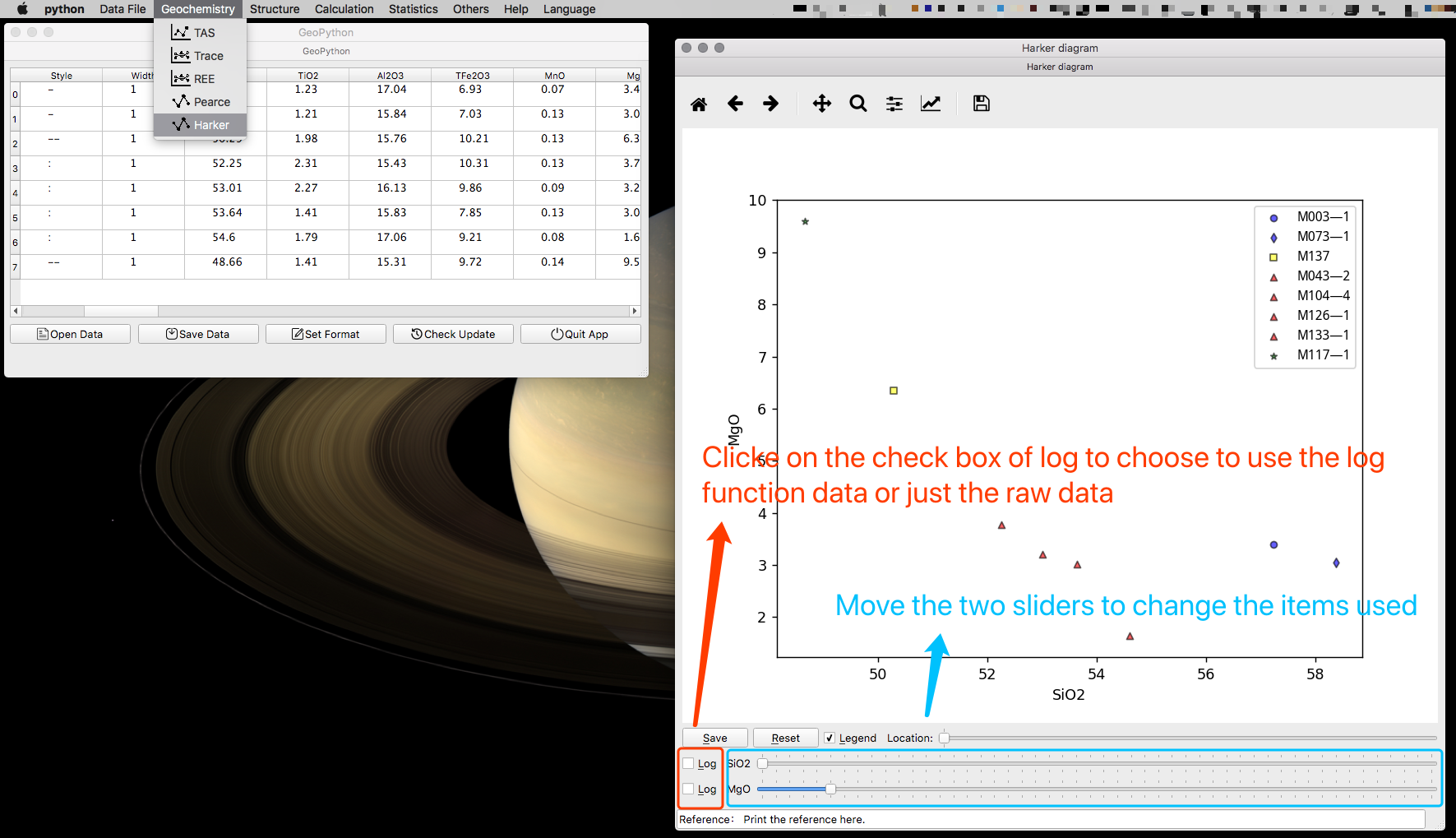
Harker 图解
这个稍微复杂点,横纵坐标轴都可以任意而选择,各自有一个滑块,如下图所示。
QFL 和 QmFLt
这两个也特别简单,导入好对应的数据,注意项目首字母都大写,别弄错了,也就可以了,没啥可说的。
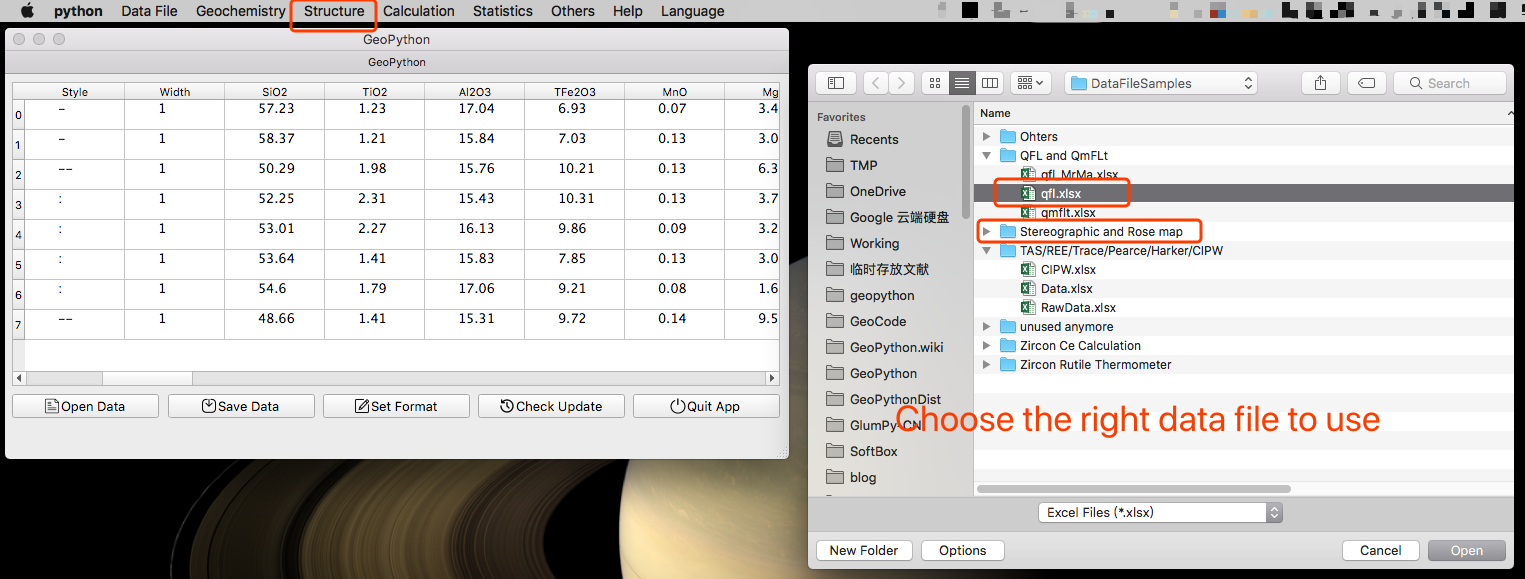
对了,如果你的原始数据没有设置分组和颜色等格式信息,记得要设置。
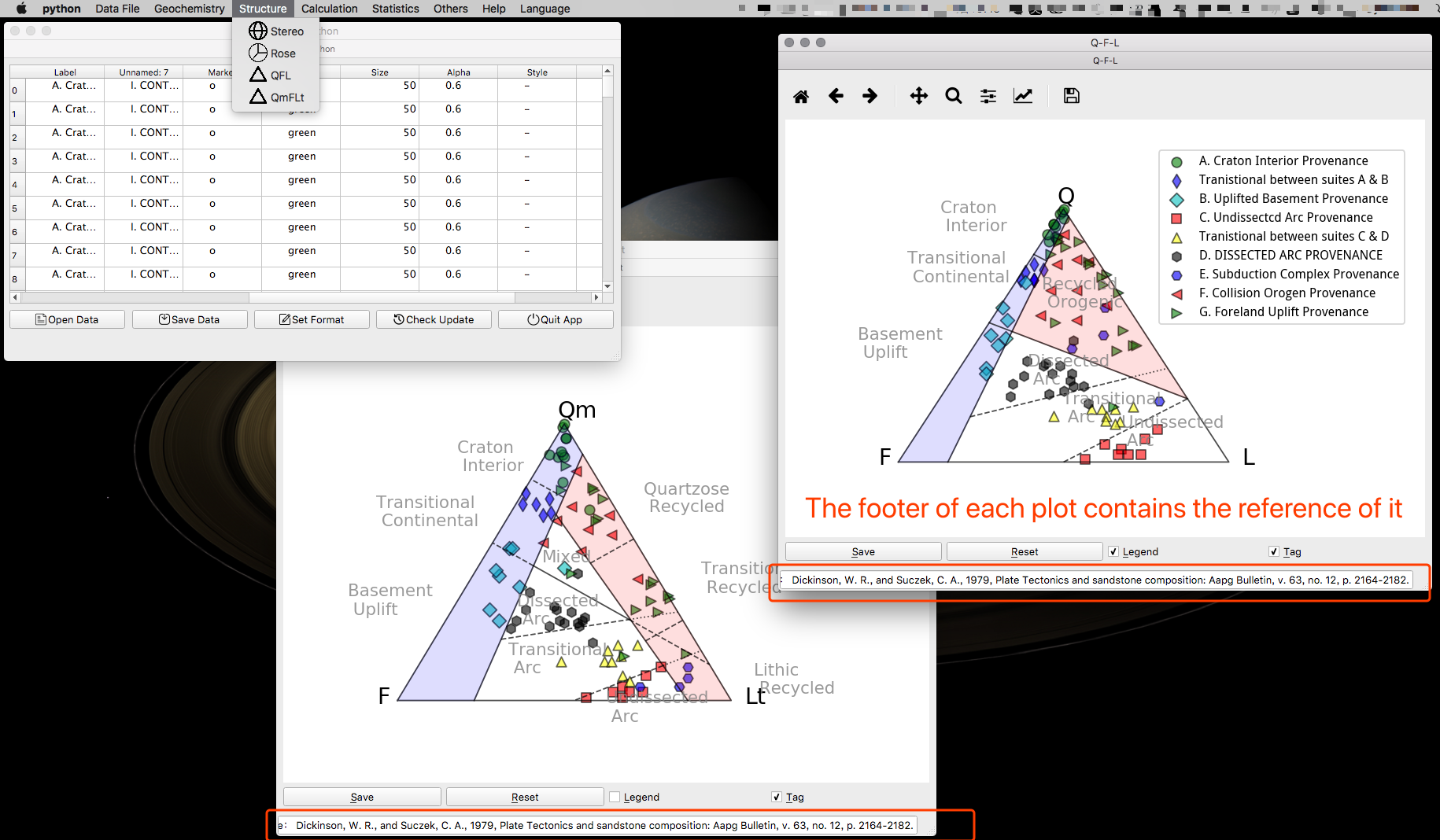
极射赤平投影和玫瑰花图
这两个功能里面有一点比较有意思的,就是可以选使用吴尔夫网或者施密特网,这两个一个是等面积网一个是等角度网,至于哪个是哪个我忘了,反正程序里面应该是对的。
Line/Point 那个选框可以切换投点还是投线在图上。
然后玫瑰花图功能稍微复杂点,可以设置把一个数据文件里面的所有数据当做一组来看玫瑰花图,这个场景估计常用一些;也可以按照文件中的分组各自分别来投玫瑰花图来一起对比。另外用于投玫瑰花图的项目还可以改变,也是通过滑块,Dip、Dip-Angle、Strike,就是倾向、倾角、走向,目前就放了这三个,当然实际上你也可以把别的变量放到这种变量名下然后生成玫瑰花图,灵活点呗。对了,玫瑰花图的步长是可以调整的,不懂什么是步长,你试试就知道了。
另外一定要注意,数据表格里面的三个项目一定是Dip、Dip-Angle、Strike,首字母必须大写哈。
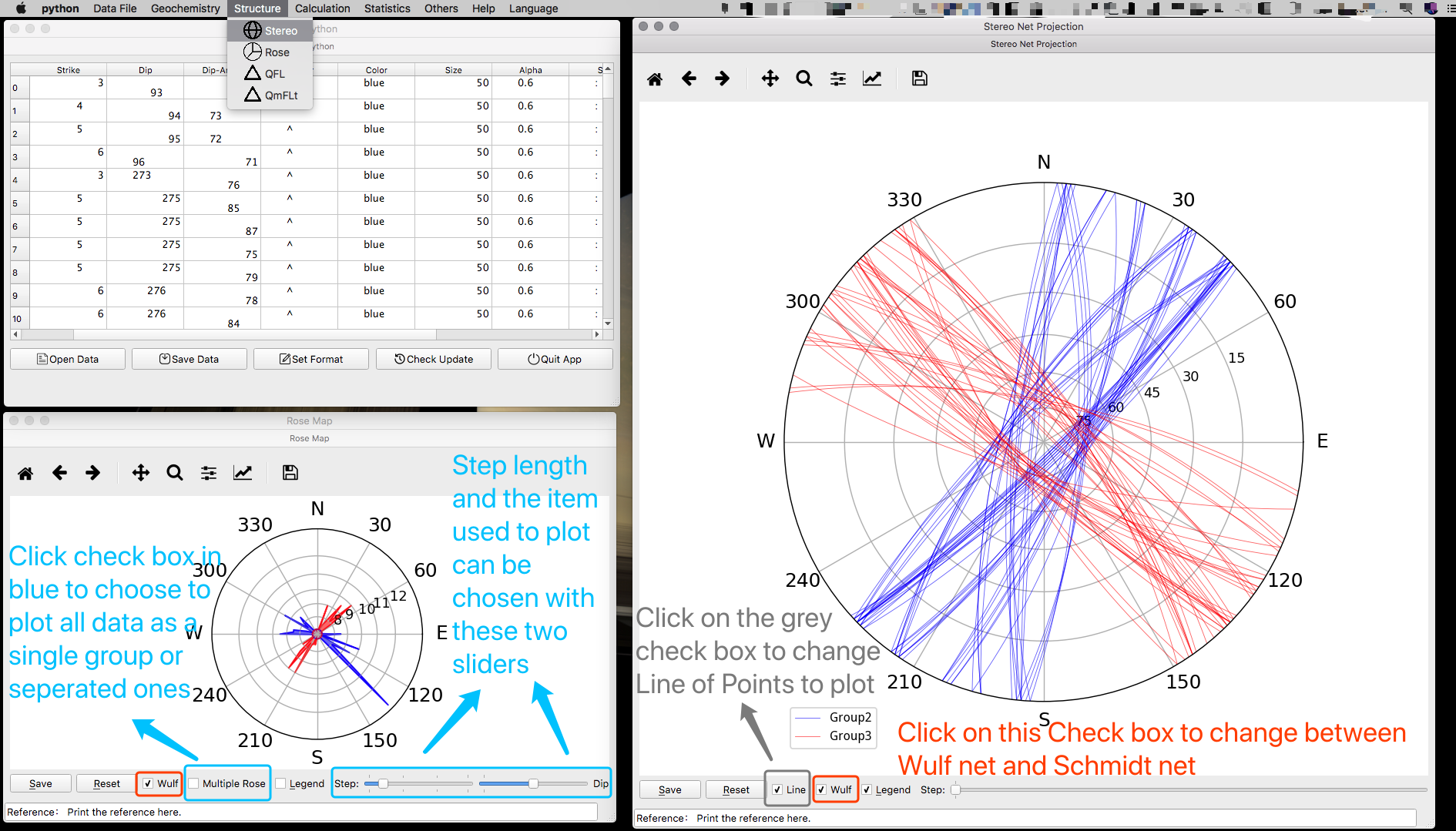
锆石 Ce4/3 比值计算氧逸度
数据挺复杂,不过按照下图所示来设置就好了。
下面的图就是 Ballard 当初那篇文章中的数据。这个版本简化过了,上一个版本的数据文件不能用了!Base 可以是全岩的稀土值和 Zr 值,也可以是斜长石的,这取决于你用哪个做基准。锆石的 Zr 值要设置成那个常量497555,不要改,其它不用于拟合计算的元素都不要留!

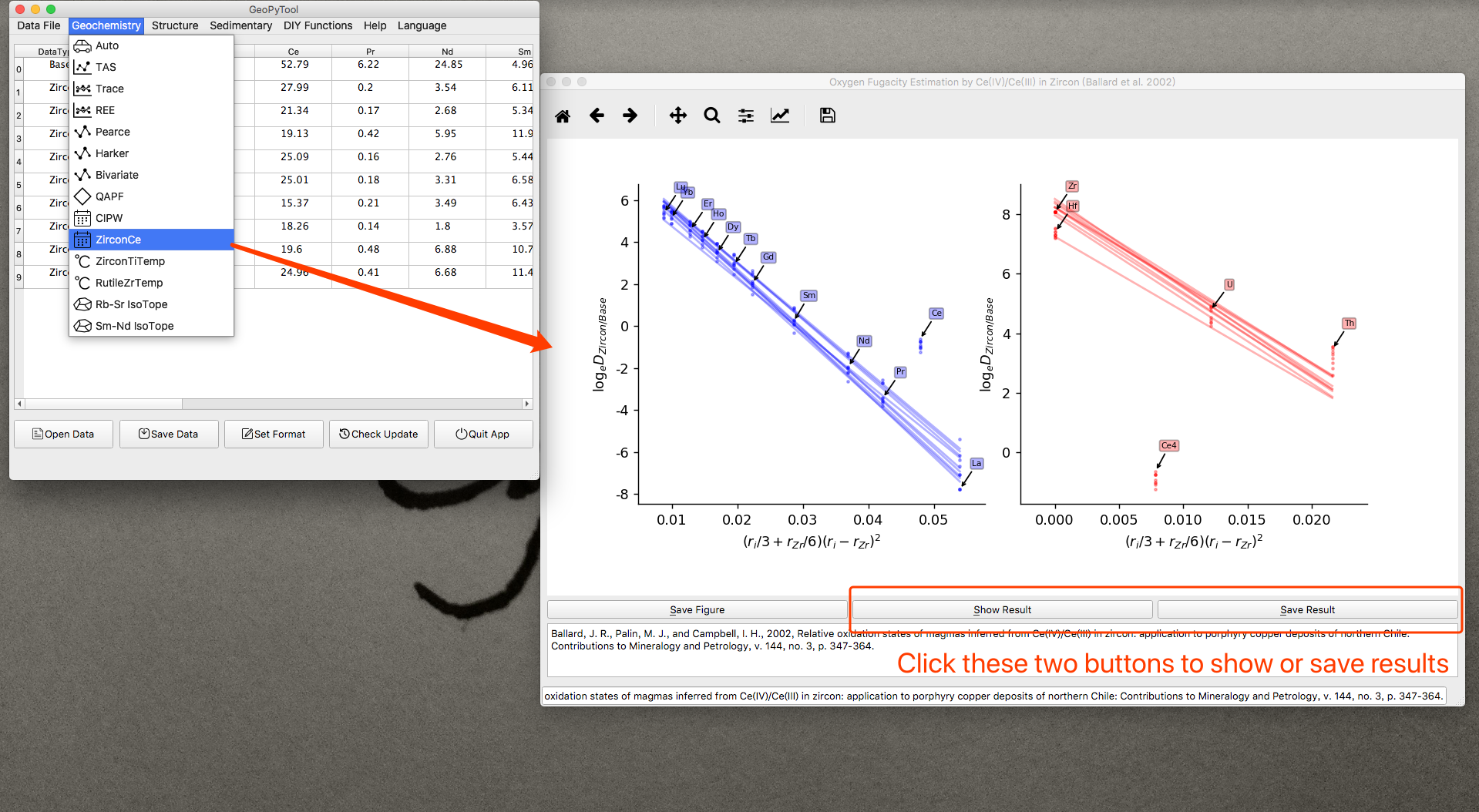
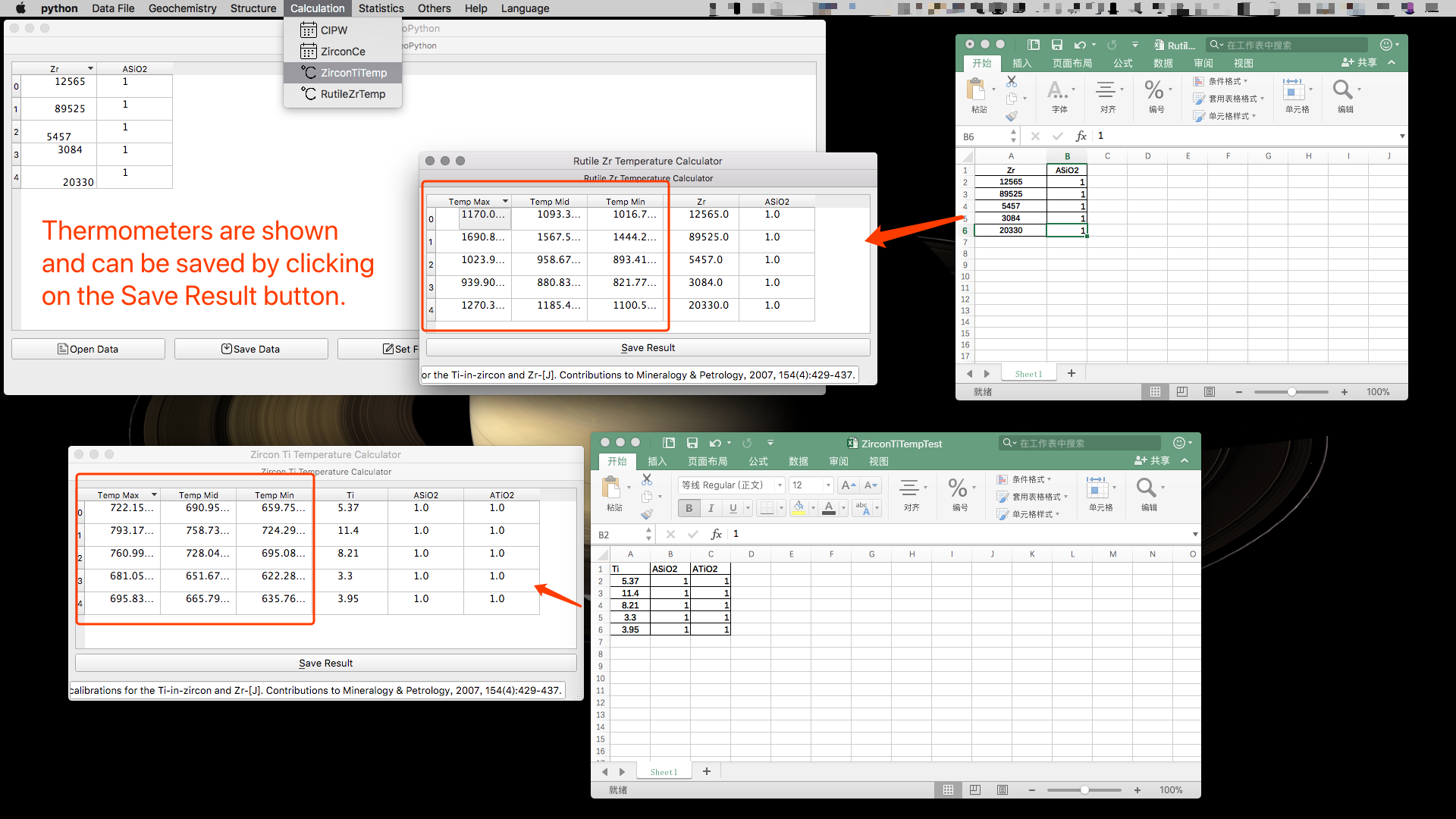
锆石和金红石温度计
没啥可说的,Zr 是金红石里面的锆元素含量,Ti 是锆石里面的钛元素含量,然后ASiO2 和 ATiO2 是这两种成分的活度。
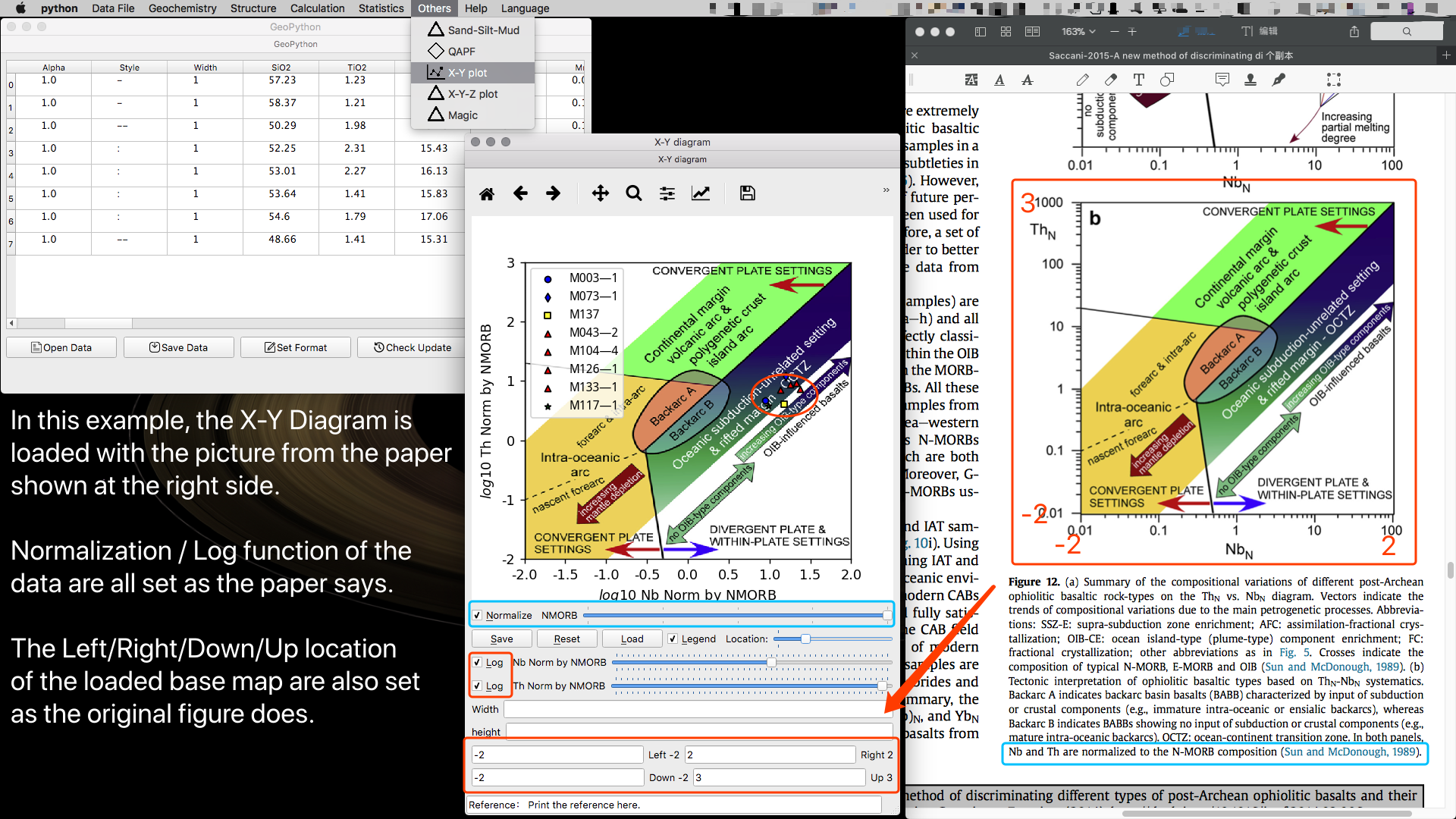
自定义平面图
这个功能允许用户加载任意图片做底图来投图。 不过你必须得明确理解原图的数学意义才行,要不然你都不知道坐标位置以及是否使用了对数函数,怎么可能糊涂地就拿来用,那还是科学么,那不是扯淡么。
例如下面这个图的原文中都在图下方说了,使用的两种元素 Nb 和 Th,利用 N-MORB(Sun and McDonough 1989) 进行了标准化,然后投图的时候很明显是用了对数函数。所以咱们在程序中也选择这样的设置。
从文中原图可以看出来,左右下上四个边界分别是 0.01/100/0.01/1000,咱们对应在直角坐标系里面就应该是 -2/2/-2/3。所以在程序里面的对应位置就输入这四个值。
你要是这些都看不出来或者看不懂,就还是回家洗洗睡吧。
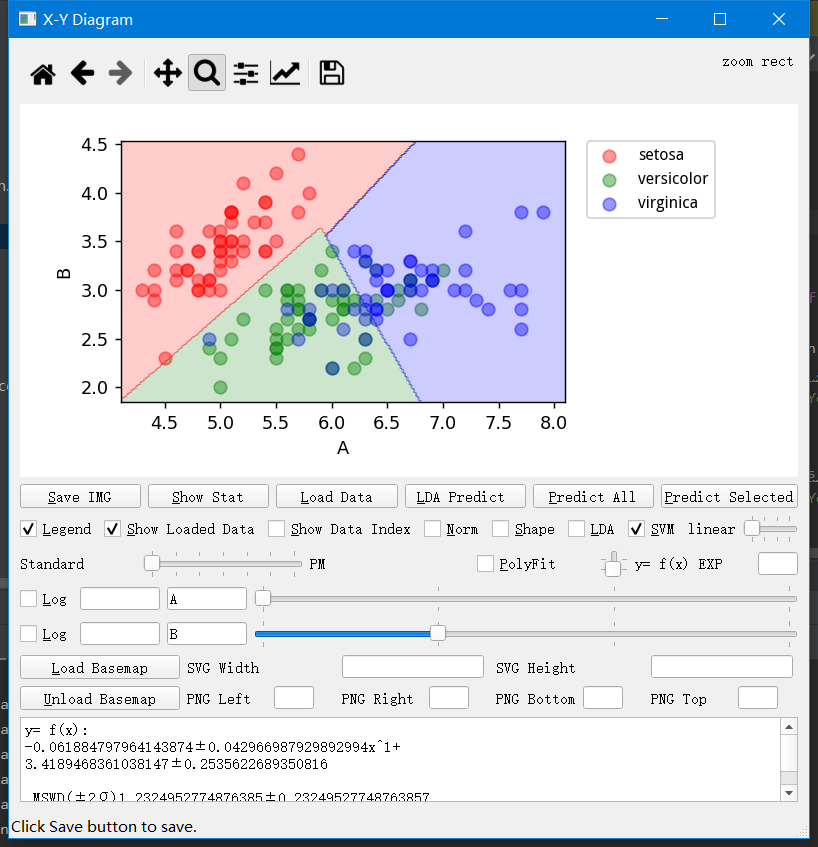
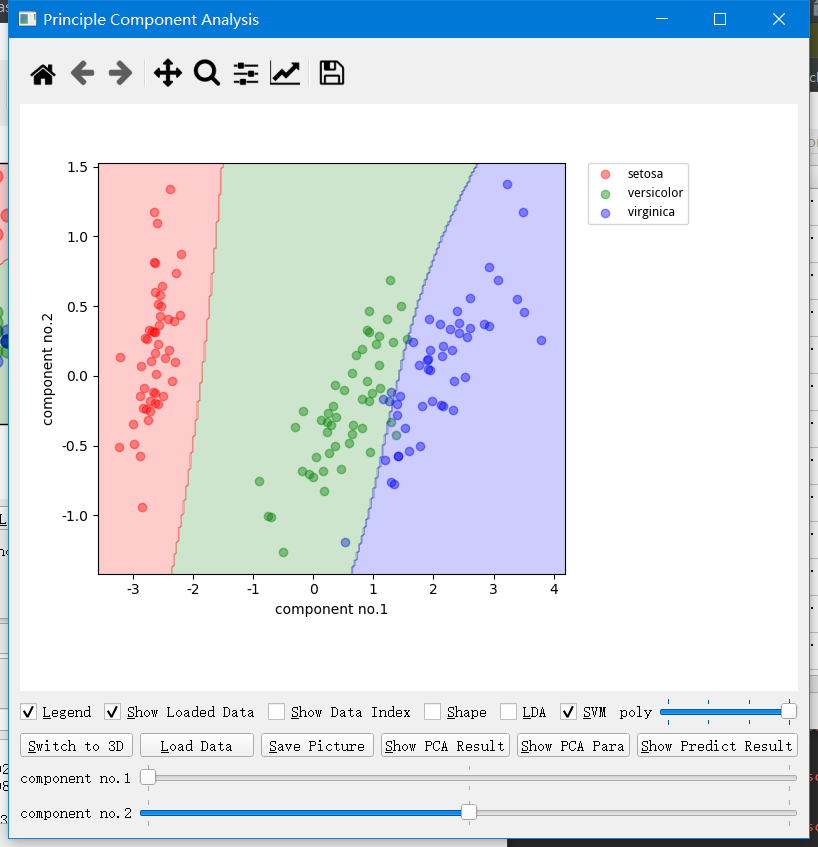
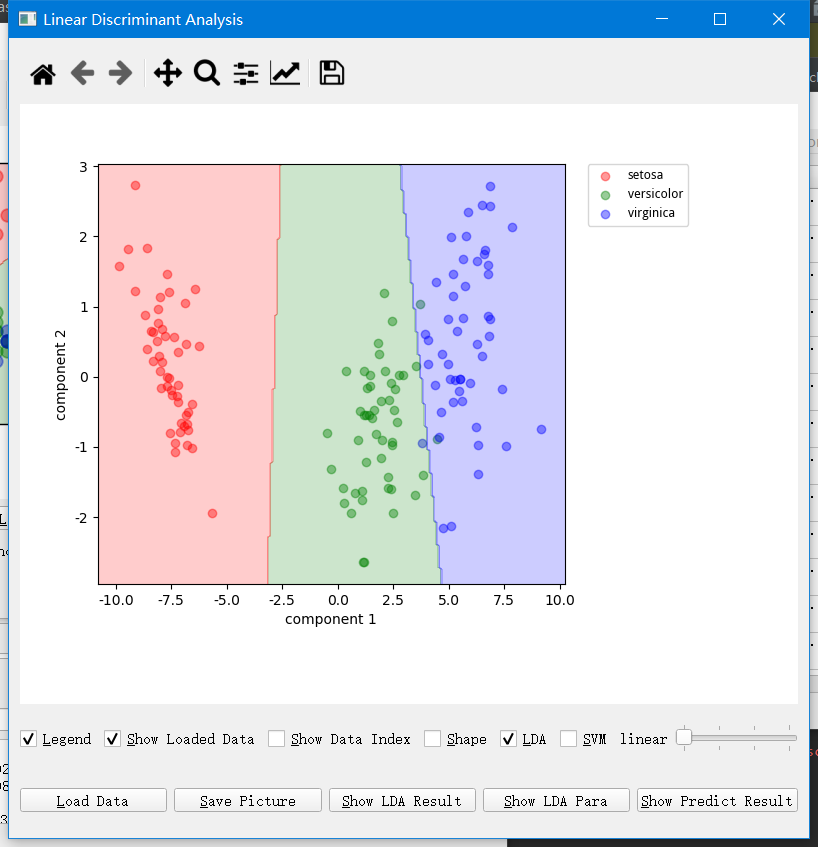
自定义图解首先需要你在主界面打开一份数据,然后生成X-Y图解,在这里可以用log勾选与否来决定是否进行对数化。旁边挨着log的是缩放倍数,这里啥也没填写就是不缩放,就直接用所选的特征了。 点击 LDA 框来生成 LDA 的结果图。 点击 SVM 框来生成 SVM 的结果图。 另外还有几个按钮,Load Data 按钮是在已经利用第一次的数据生成边界和模型的基础上,再加载一份未分类的数据。 然后点击 LDA Predict 按钮就按照当前所选的显示维度来进行 LDA 预测。点击 Predict Selected 按钮是按照当前图解上显示的所选特征维度来进行 SVM 分类预测。 点击 Predict All 是按照当前数据的全部特征来进行分类。
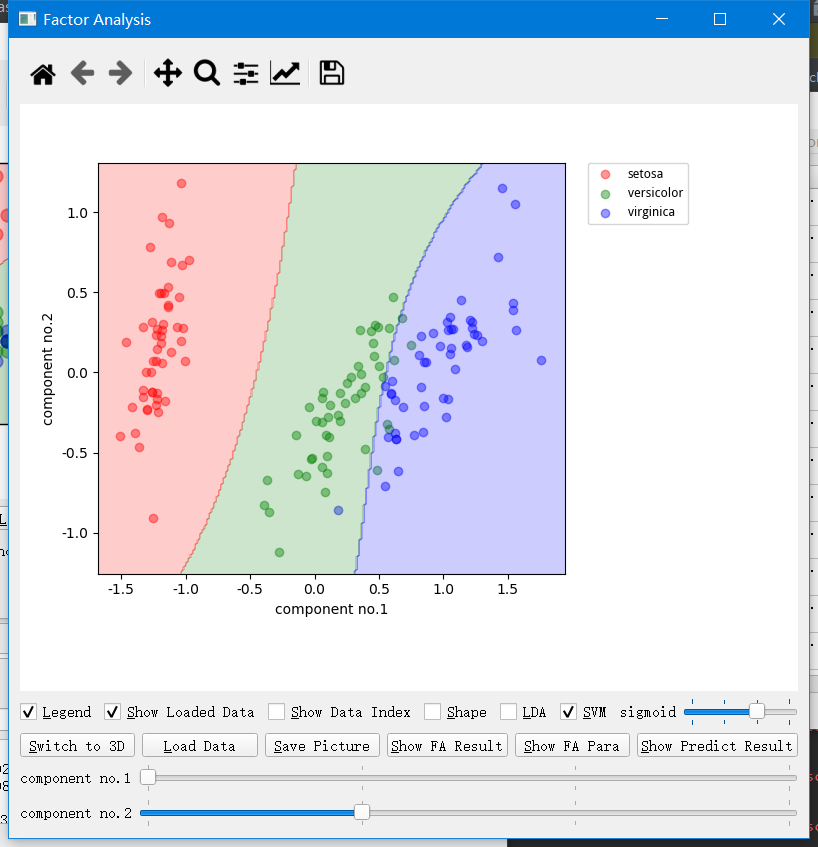
其他的几个 FA/PCA/LDA 功能和 X-Y 图解差不多.
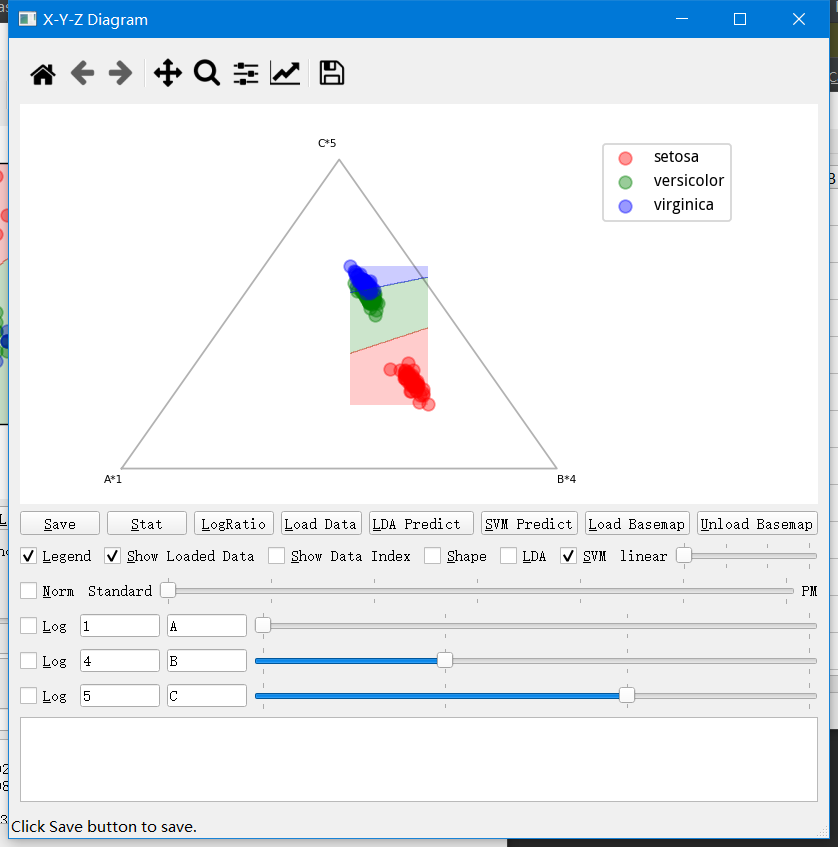
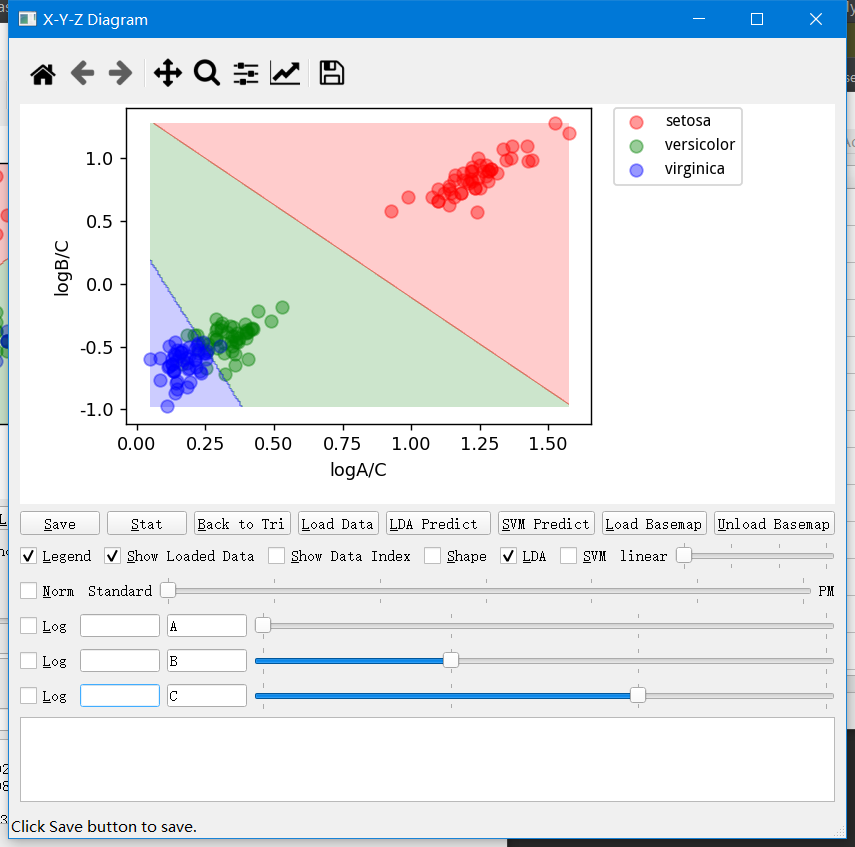
User Defined X-Y-Z diagram
这部分的功能和上面 X-Y 的情况其实差不多。有点差别的就是加入了对数比变换(log ratio)来从三端元映射到两组实数。实际上二元图解明显在数学上更优美,更具有可解释性。三单元图解的内部空间和位置关系都与现实关系有不同程度的缩放。
3D 和统计
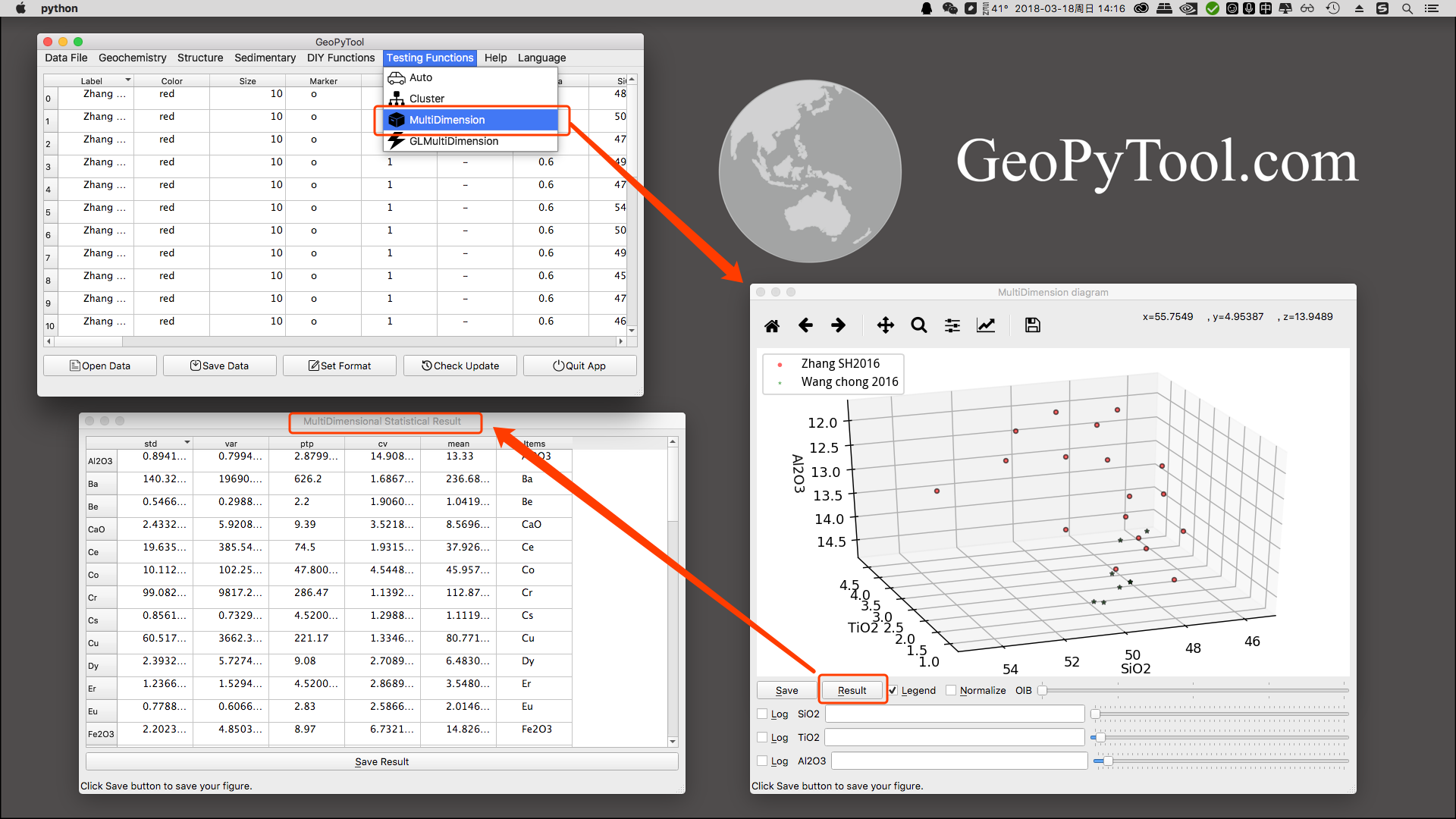
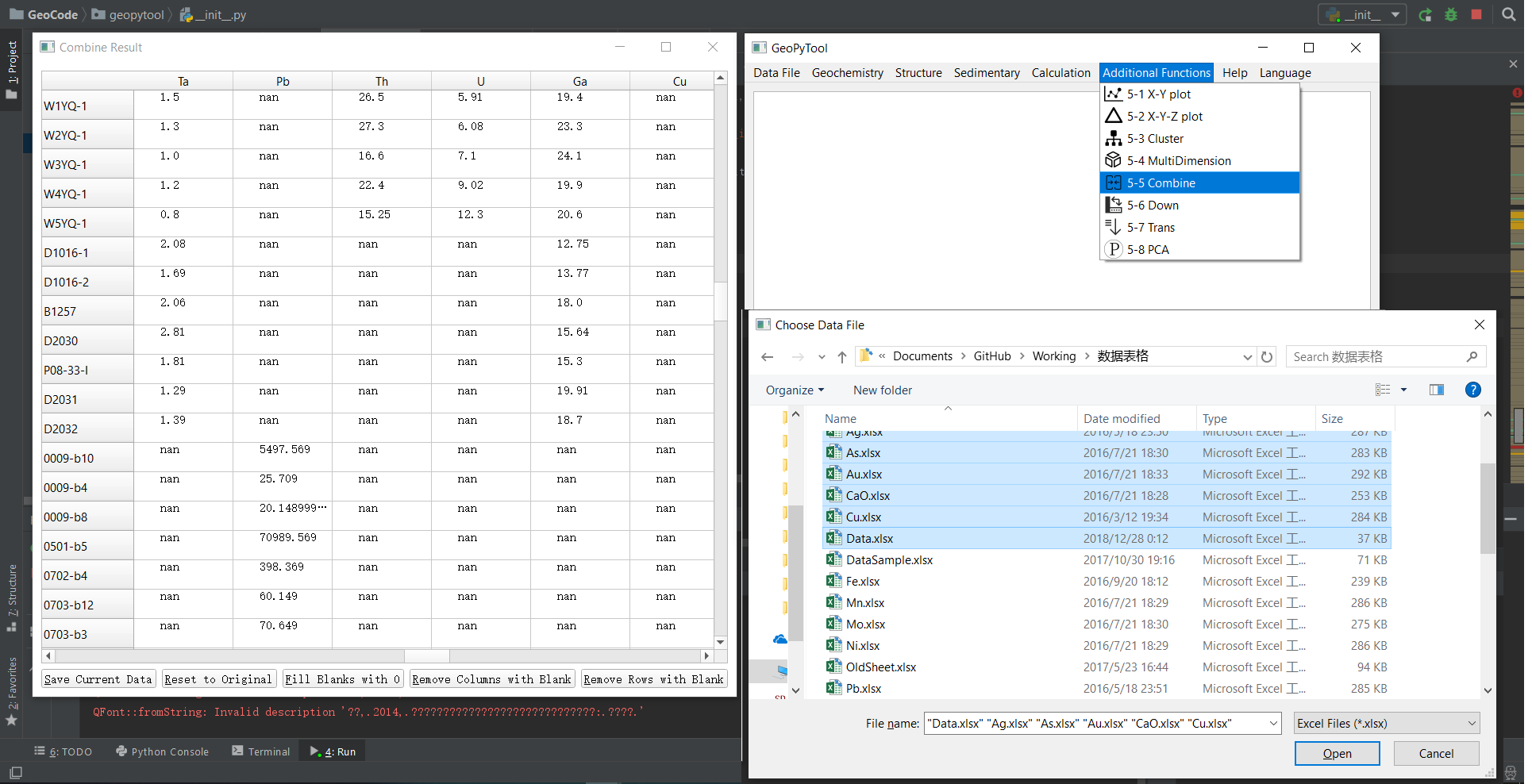
将多个 Excel 数据文件合并成一个文件
谱系聚类

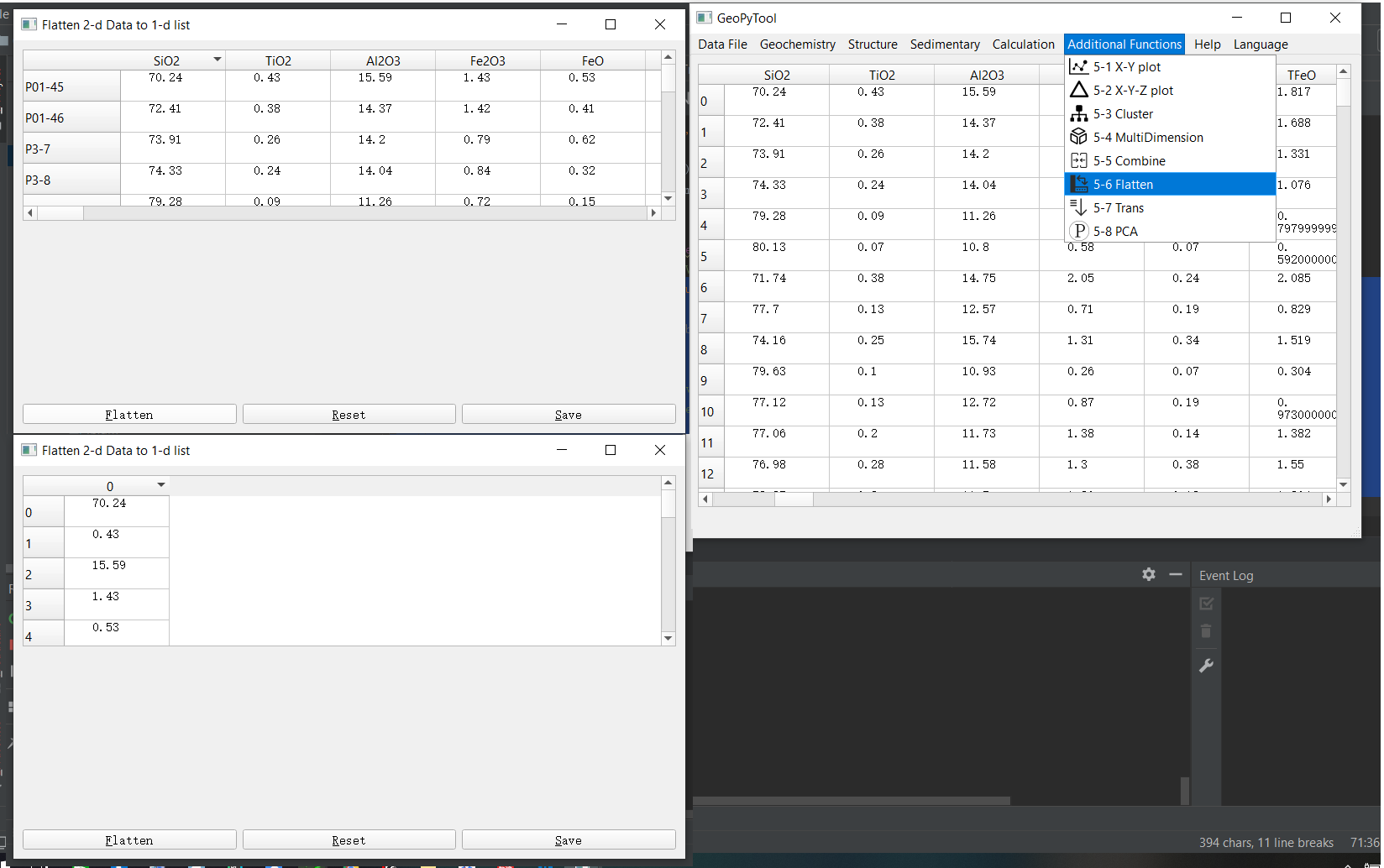
二维矩阵拉平成一维数组
数据变换: 转置/算术平均值中心化变换/几何平均值中心化变换/标准化变换/对数变换
![]()
因子分析 (FA) 和主成分分析 (PCA)

捐助支持
如果你希望支持 GeoPyTool 的开发,可以扫描下面的二维码进行捐助。
